
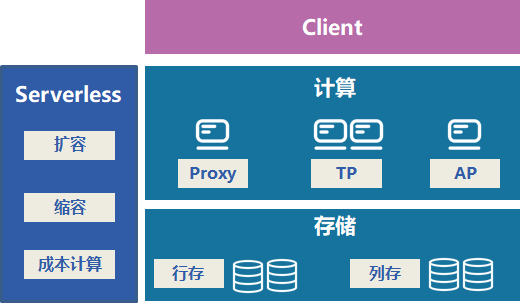
Hello everyone, I would like to introduce the project serverlessDB for HTAP. serverlessDB is a database for severless services based on TiDB, which can dynamically scale up and down compute and storage nodes based on business load changes with zero user perception. It provides the following features.
- Dynamic scaling based on business load to ensure continuous and stable business with zero user perception.
- The service load model can differentiate between AP and TP services, ensuring that AP and TP services do not affect each other.
- Always ensure that the load on each computing node is balanced and kept within a reasonable range.
- Supports ultra-small form factor compute nodes and ensures smooth transition from ultra-small to large form factor.
In order to implement tidb serverless, we designed the proxy module and serverless module. The proxy module does permission control, computation under low load, and traffic forwarding under high load, while the serverless module mainly manages tidb-server instances and smoothly scales tidb-server.Below is an overview of the system design.
proxy module
-
Low-load computing
The proxy module acts as a tidb-server under low load, interacting directly with pd and tikv and returning sql execution results to the client.
-
High-load traffic forwarding
Under high load, the proxy module mainly implements sql processing and traffic forwarding functions. sql processing mainly includes sql parsing, sql optimization, sql execution plan generation, and estimation of sql execution cost, while traffic forwarding mainly carries out load balancing according to the cost of sql, and forwards the sql execution plan to the regular tidb-server instance for execution.
-
Medium-load
The proxy can be used as both a compute node and a proxy node. For example, for some point-check SQL, the proxy directly completes the calculation without forwarding to other tidb nodes. Some relatively complex SQL is forwarded to other nodes.
-
The proxy will establish connections to other TIDB nodes, each corresponding to a pool of connections. After the user request comes in, a series of calculations are performed, and finally, based on the cost, a suitable TIDB node is selected, and then a connection is selected from the pool of connections corresponding to this TIDB node for the specific task.
From the above description, there will be three roles for the proxy: pure compute node role, pure proxy role, and mixed compute and proxy role. These three roles will be dynamically adjusted online based on the business load.
serverless module
-
tidb-server instance management
Control the specification of compute and storage instances and the number of instances, support load-based and rule-based elastic scaling, support compute/storage node scale up/down, scale out/in.
-
Smooth expansion and contraction tidb-server
When expanding, the serverless module registers new instances with the proxy module, and when scaling down, the serverless module deletes instances with the proxy module. After each operation, the proxy module will dynamically load balance to existing instances to achieve smooth business migration.
The lastest progress of this project is:
- Complete development of serverless module
- tidb is being modified to make tidb proxy capable (connection pooling development completed)
Limitations:
1.It is difficult to cope with scenarios where the business load changes dramatically, e.g. TPS rises from 100 to 100W in a very short period of time, leading to business performance fluctuations and some SQL delays reaching 5s and lasting up to 30s.
2.It is difficult to establish the most correct business load model and there is a risk of unbalanced load on some of the computing nodes.
3.Because of the introduction of the proxy, there will be performance loss, ideally, performance loss is expected to be kept within 15%.
TODO:
- Distinguish SQL between AP and TP.
- Optimize the business load model.