
Hello everyone! This is Sandy from JuiceFS team. We are developing a new metadata engine for JuiceFS based on TiKV. Here is some background information.
JuiceFS is a distributed POSIX file system specially optimized for cloud-native environment. In JuiceFS, data is persisted in object storage (e.g. Amazon S3), and metadata can be stored in various databases such as Redis, MySQL or TiDB. JuiceFS is used in a lot of scenarios like big data analytics, machine learning, shared storage, etc. Below is the an overview of the system architecture:
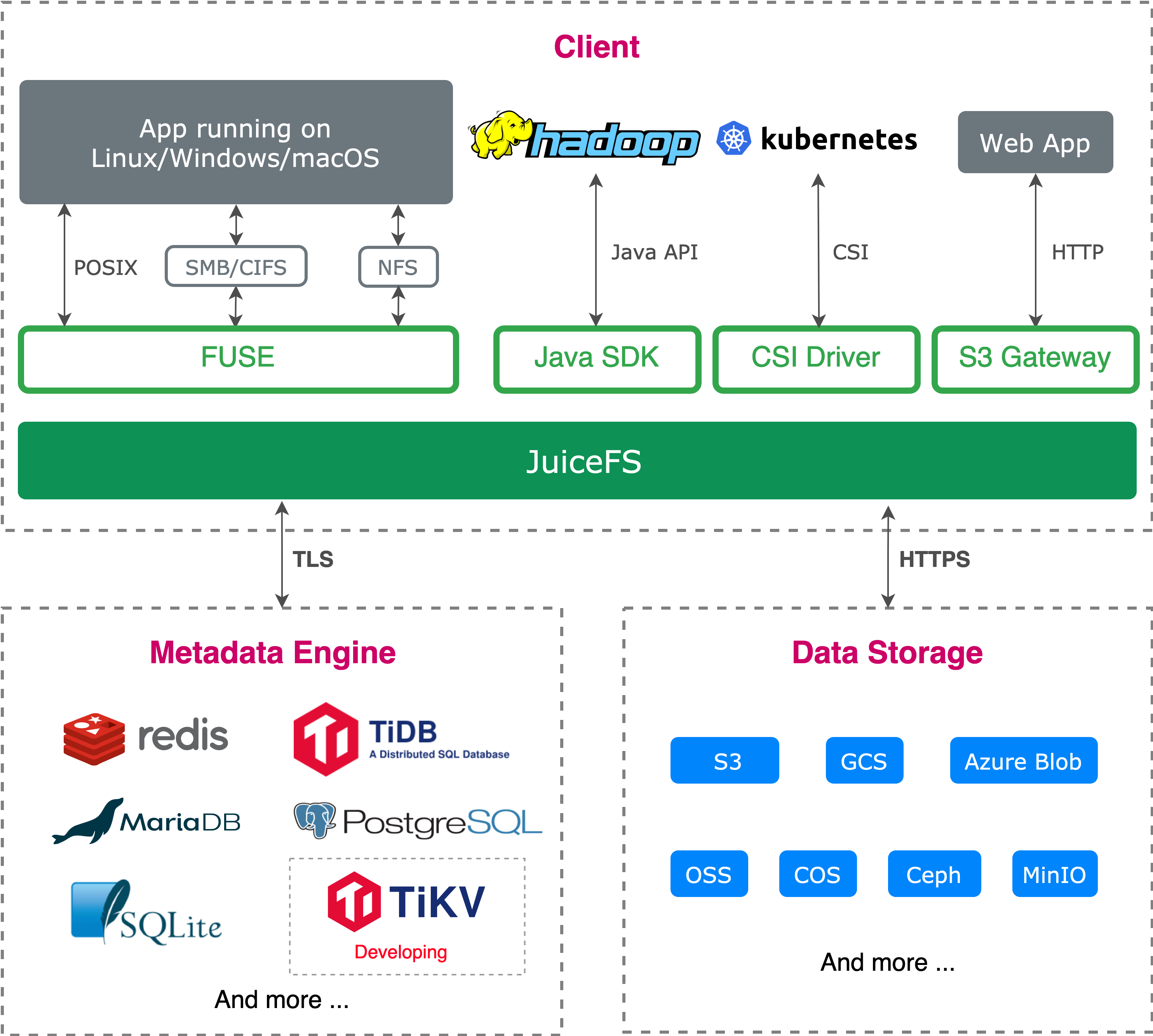
Metadata engine is a critical component for distributed file systems. JuiceFS chooses Redis as the first one, considered that it has good performance and has been widely used in many organizations. However, Redis is not suitable for scenarios requiring high reliability or storing more than billions of files. Thus, a SQL interface (supporting SQLite, MySQL, TiDB, PostgreSQL, etc.) was developed as the second metadata engine. Although TiDB is a great choice for users who prefer reliability and scalability, we believe TiKV should have the same superiorities, but simpler architecture and higher performance.
Currently the new metadata engine is under development, more information can be found here. Any contribution and discussion are welcomed, you may leave comments under the thread or contact us directly.
