
Background
The TiDB ecosystem did not have a scalable continuous incremental backup solution. TiDB Binlog and TiCDC both require setting up an external cluster to capture the changes, increasing the complexity and adding new point of failure. BR’s existing “incremental” backup requires full-table scanning which is heavyweight and not very real-time.
We want to have a streaming backup system which
- can scale up with the cluster
- native, does not require an external processor, to reduce the number of “moving parts”
- light-weight, continuous backup in should not affect latency
- low-level, keeping the details of the original cluster as much as possible, reducing backup and restore complexity
- support point-in-time recovery
Design
The first draft of the design can be found in https://pingcap.feishu.cn/docs/doccnMvA0vKi8cnzIb2fAfUC6nd.
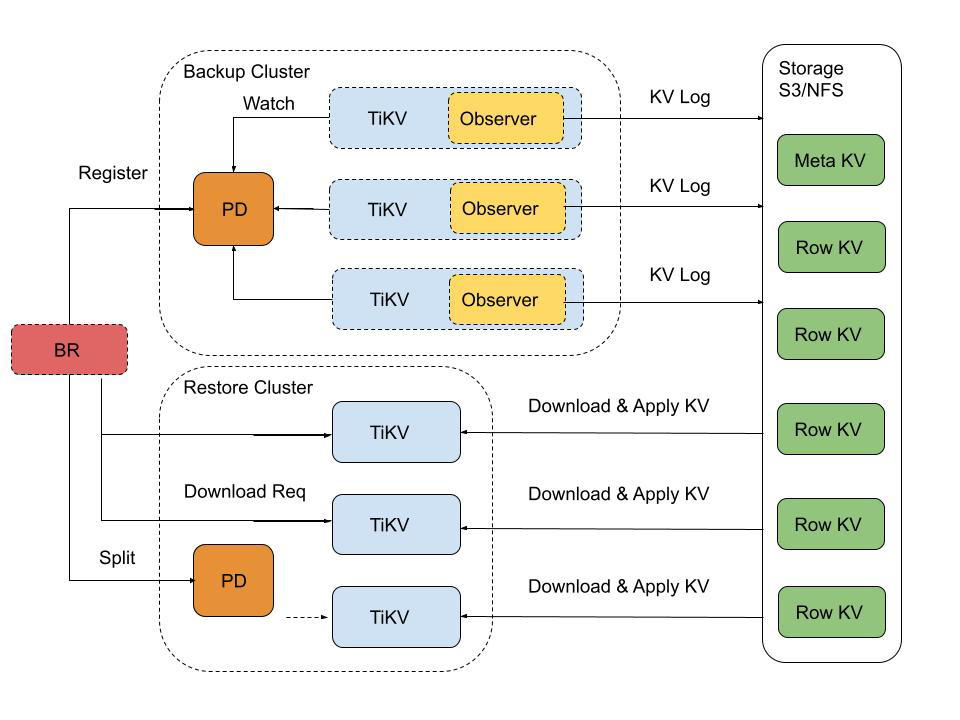
Briefly, on every TiKV we will add a CmdObserver (like the existing cdc crate), copying Put and Delete events for every region it is leader of into a local buffer. The buffer is flushed every 5 minutes or 128 MiB to cloud (S3 / GCS / NFS).
The backup state and progress is saved on PD or an external etcdv3 cluster, so TiKV backup is mostly pull-based and stateless.
Restore (to a private empty cluster) is done by replaying these events in RawKV.
Please read the Feishu Doc for detail.