
Code reading: Why panic when got singlerecord?
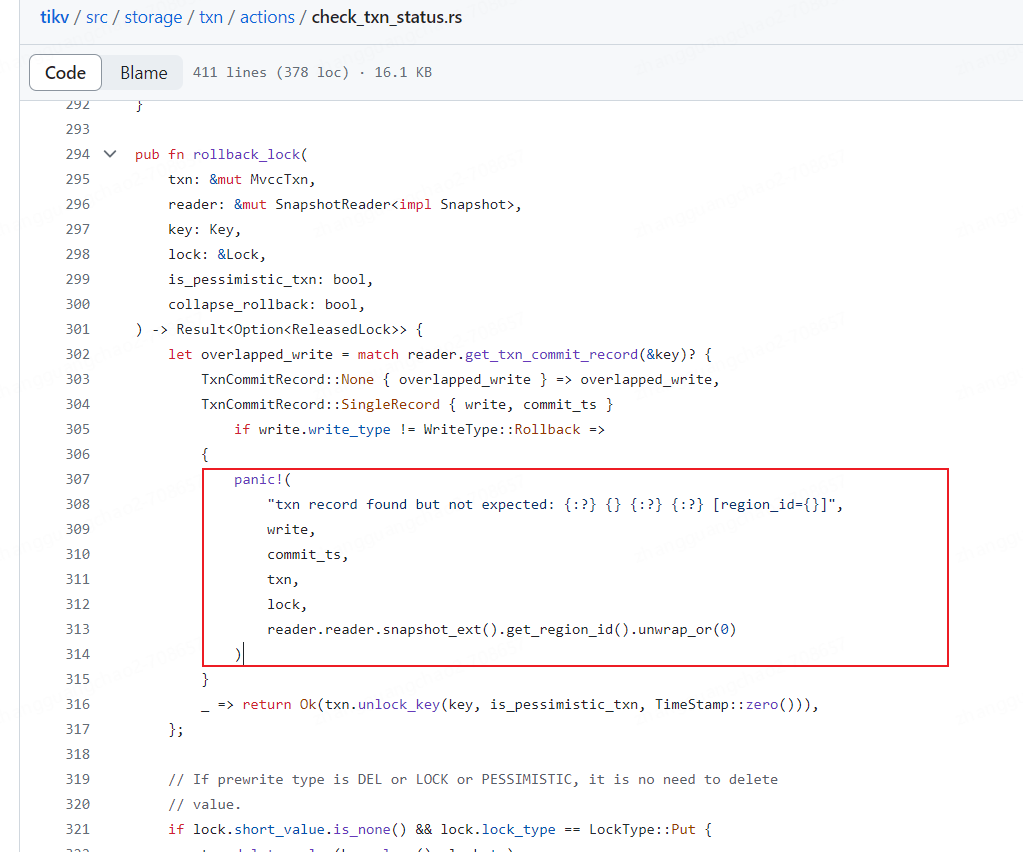
This situation implies that there are inconsistency states, meaning the lock that was expected to be rolled back is found in the storage layer associated with the commit record of the same transaction. It’s not straightforward to clean up or commit the lock, hence the panic.
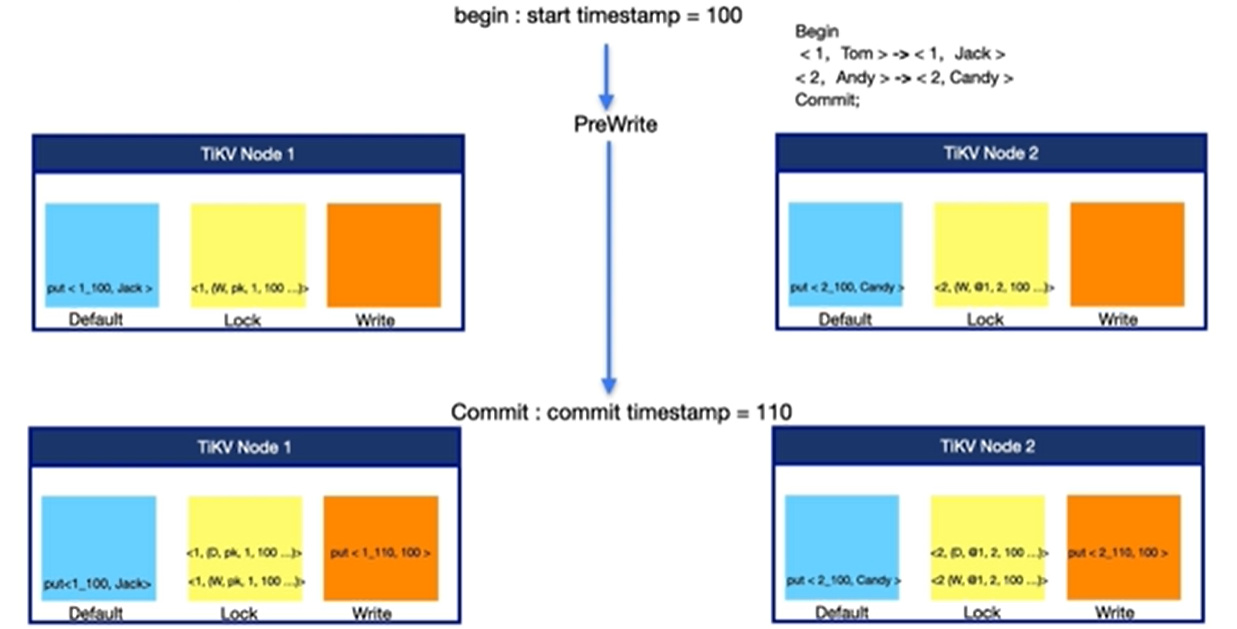
After looking at the code, I understand that the bug was caused by me. The data in lock cf was not deleted, but the commit records were written in write cf. This caused a problem with the transaction.
Normally, the deletion of data in lock cf and the writing of commit records in write cf should happen together in the same write batch, and be submitted to rocksdb. It should not occur that lock cf was not deleted while write cf was committed. Therefore, it should panic. It was this panic that helped discover this bug, so kudos to the developers of tidb!